

Заявка на звонок консультанта
Оставьте свои данные, мы свяжемся
с Вами в ближайшее время
с Вами в ближайшее время
Платформа опросов с ИИ: насколько меняется точность анализа после обучения модели.
9 минут
01.12.2025
- Никита ЛихановCustomer Research Manager в ФОКУЗРазвиваю направление исследований клиентского опыта и UX в ФОКУЗ. Специализируюсь на исследованиях клиентского опыта (CX), методиках опросов и анализе обратной связи.
Содержание
- ИИ: просто, удобно и время экономит
- Как это сделано
- Методология исследования
- Экспертная разметка
- Промты: как мы обучали ИИ понимать ответы
- Почему такой подход работает
- Два этапа тестирования
- Метрики качества: что и почему мы измеряли
- Метрики для тональности: точность — вежливость королей
- Категоризация: не только точность, но и полнота
- Результаты базовой модели
- Результаты дообученной модели
- Влияние дообучения
- Ключевые улучшения
- Выводы и практическое применение
- ИИ: просто, удобно и время экономит
- Как это сделано
- Методология исследования
- Экспертная разметка
- Промты: как мы обучали ИИ понимать ответы
- Почему такой подход работает
- Два этапа тестирования
- Метрики качества: что и почему мы измеряли
- Метрики для тональности: точность — вежливость королей
- Категоризация: не только точность, но и полнота
- Результаты базовой модели
- Результаты дообученной модели
- Влияние дообучения
- Ключевые улучшения
- Выводы и практическое применение
Искусственный интеллект давно перестал быть фантастикой — сегодня он помогает не только рисовать картинки, оживлять фотографии и создавать видео, но и принимать реальные бизнес-решения. Особенно там, где важна скорость, точность и анализ больших объёмов данных: в маркетинге, HR, UX- и CX-исследованиях.
Исследования потребностей клиентов, их удовлетворенности — важная часть бизнес-процесса. Мы — команда разработчиков технологической платформы опросов для бизнеса ФОКУЗ. И сегодня мы расскажем о том, как внедрили блок ИИ в процесс анализа пользовательских ответов, дообучили нейросеть и к чему это в итоге привело.
ИИ: просто, удобно и время экономит
Триггерные опросы помогают быстро получать обратную связь от пользователей. Раньше анализировать текстовые ответы приходилось вручную: распределять по категориям, добавлять теги и группировать, чтобы увидеть, как меняется клиентский опыт или настроения респондентов. Теперь с нейросетями это стало намного проще. Мы добавили в платформу опросов ИИ‑блок — так обработка данных занимает меньше времени и даёт более точные результаты.
Как это сделано
В сервисе опросов ФОКУЗ реализован функционал автоматического анализа текстовых ответов с помощью ИИ. Этот инструментарий помогает быстро анализировать большие объемы текстовых ответов, выявлять тренды и принимать решения на основе обратной связи.
Система определяет:
-
 Тональность ответа — позитивная, негативная или нейтральная эмоциональная окраска;
Тональность ответа — позитивная, негативная или нейтральная эмоциональная окраска; - Категории (теги) — от 0 до 5 смысловых тегов из предопределенного списка.
Для улучшения результатов ИИ анализа мы провели дообучение модели и сравнили результаты анализа до и после. Фраза прозвучит банально, но результаты действительно превзошли наши ожидания: точность категоризации удалось повысить на 38%, определение тональности — на 4%.
Методология исследования
Кейс исследования: опрос о смене фирменного стиля
Для исследования использовались данные реального опроса нашего клиента на тему новой дизайн-концепции бренда. Клиент - федеральная сеть магазинов у дома. В эксперименте использовались два опроса: в одном предлагалось оценить стиль в одних тонах, во втором - в других.
Структура каждого опроса:
- Текстовый экран с описанием
- Вопрос про возраст респондента
- «Тест пяти секунд»:Респонденту без ограничения времени показывается набор изображений с новым дизайном.Далее задается вопрос: «Опишите тремя словами ваше первое впечатление от дизайна бренда» с ограничением ответа 250 символов.
- Дополнительные вопросы (не используются в анализе)
В ходе исследования было получено:
- 2700+ текстовых ответов
- 1350+ респондентов на каждый опрос
- 58 категорий для анализа

Статистика кейса
Экспертная разметка
Клиент предоставил выгрузку ответов, где для каждого текстового ответа эксперт проставил:
- Тональность (одна из трех: позитивная, негативная, нейтральная)
- От 0 до 5 категорий из списка 58 возможных тегов
Эта экспертная разметка стала эталоном для оценки точности ИИ.
Примеры категорий из списка 58 тегов: яркость/красочность; подростковое/детское; вырвиглазно; солнечно; лето; отвращение/противно; молодежно; красиво; агрессивно/раздражает; свежесть; современное; стильно/модно; необычно/оригинально; креативно; простота и другие...
Промты: как мы обучали ИИ понимать ответы
Ключевой элемент работы ИИ — это промты (инструкции), которые объясняют модели, что и как нужно делать. Мы разработали два специализированных промта с четкой структурой и обоснованием каждого элемента. Они использовались как для базовой модели, так и в качестве основы для дообучения.
Промт для определения тональности
Структура промта:
Задаем контекст и роль
"Ты — эксперт по анализу пользовательских впечатлений и эмоциональной окраске текста"
Роль и контекст необходимы для того, чтобы модель лучше понимала ваши ожидания и использовала соответствующие знания и стиль анализа.
Даем чёткие определения категорий с примерами
- Позитивные: одобрение, восхищение, приятные эмоции. Примеры: «Лето Яркость», «Ярко, красиво, свежо», «Стильно, модно, молодежно»
- Негативные: недовольство, отвращение, раздражение. Примеры: «Мне не нравится», «Ужас, противно, некрасиво»
- Нейтральные: факты без эмоций, смешанные впечатления. Примеры: «Размыто, нечетко, желто», «Осень»
Примеры из реальных данных помогают модели понять паттерны каждой категории. Модель учится на конкретных случаях, а не только на абстрактных определениях.
Даем конкретные инструкции для сложных случаев
- Анализировать эмоционально окрашенную лексику («ужас», «красиво»)
- При смешанной тональности определять преобладающую эмоцию
- Пустые ответы → нейтральные
Как показывает практика, именно граничные случаи являются основным источником ошибок. Поэтому важно задать четкие явные правила, чтобы снизить неопределённость.
Промт для категоризации
Структура промта:
Гибкость в количестве тегов
«Присвоить от 0 до 5 наиболее подходящих категорий»
Не все ответы нуждаются в 5 тегах. Гибкость в количестве тегов (0–5) позволяет избежать «натягивания» нерелевантных категорий.
Указание на нюансы категорий
«Яркость, красочность» — нейтрально-описательная, а «вырвиглазно» — резко негативная оценка той же яркости.
В исследовании используются 58 категорий, которые имеют смысловые пересечения. Без пояснений модель может путать схожие, но различающиеся оттенками категории.
Примеры правильной категоризации
- «Ярко, красочно, лето» → Яркость/красочность, лето
- «Слишком яркий, раздражающий» → Вырвиглазно, агрессивно/раздражает
- «Стильно модно молодежно» → Молодежно, стильно/модно
Для обучения модели использовался метод обучения на малом числе примеров — Few-shot learning. Примеры показывают логику выбора тегов, позволяя модели лучше понять контекст задачи и более эффективно проводить категоризацию.
Акцент на точность, а не полноту
«Выбери только релевантные категории. Если подходит одна — выбери одну».
Без этой инструкции модель стремится «заполнить все слоты», что ведет к ложным срабатываниям и низкой точности категоризации.
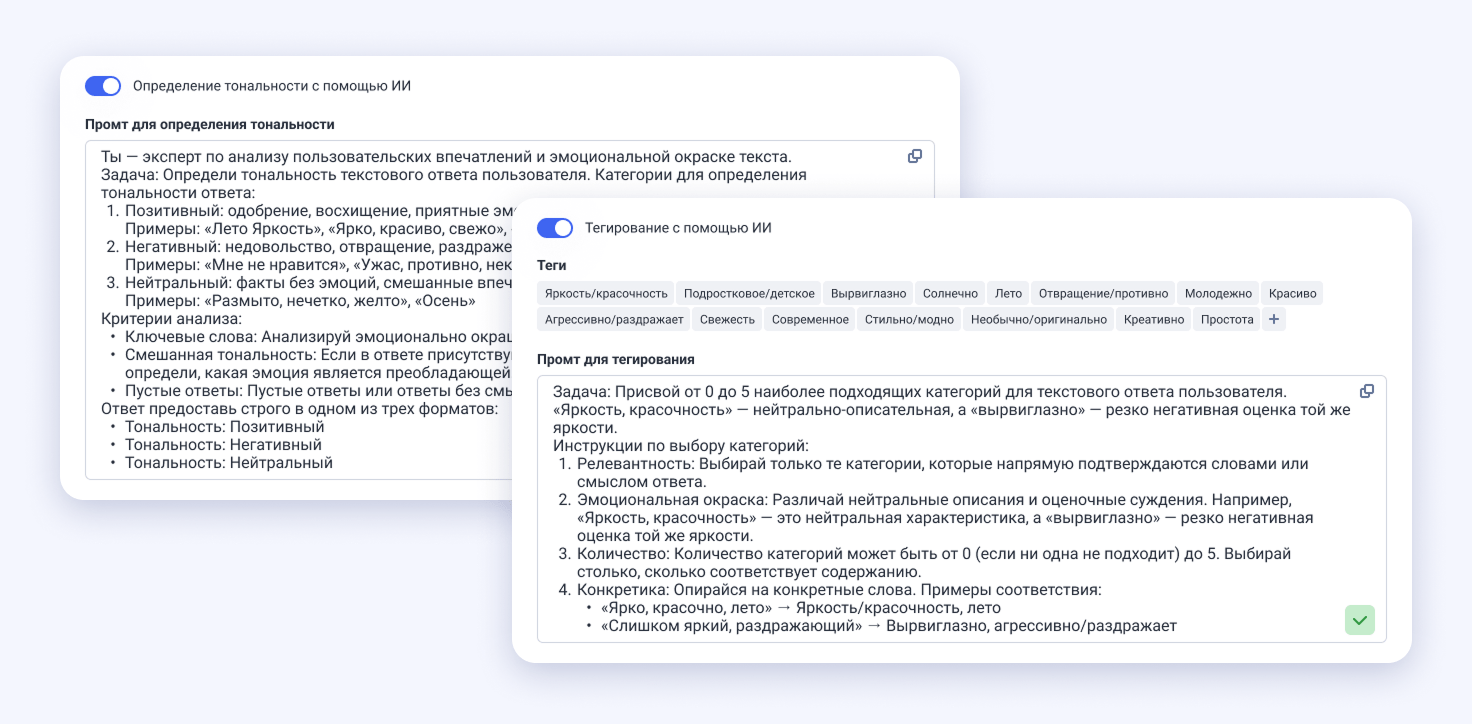
Примеры промтов — на тональность и на категоризацию
Почему такой подход работает
Эффективность промтов основана на трех принципах:
- Контекст + примеры — модель понимает не только «что делать», но и «как должен выглядеть результат».
- Явные правила для граничных случаев — снижение неопределенности в сложных ситуациях.
- Баланс точности и полноты — инструкции настроены на оптимальное соотношение точности (Precision) и полноты (Recall).
Два этапа тестирования
Исследование проводилось в два этапа:
- Базовая модель (YandexGPT Pro 5.1) — анализ всех 2700+ ответов с использованием промтов без предварительного обучения.
- Дообученная модель (YandexGPT Lite 5) — обучение на 60% данных (1620 текстов) и тестирование на оставшихся 40% (1080 текстов).
Важно: Дообученная модель тестировалась только на данных, которые она НЕ видела при обучении. Это гарантирует объективность оценки и позволяет оценить эффективность дообучения.

Модели ИИ
Метрики качества: что и почему мы измеряли
Для оценки качества работы ИИ мы использовали следующие метрики:
- точность — для тональности;
- точность и полнота — для категоризации.
Расскажем об обеих более подробно
Метрики для тональности: точность — вежливость королей
Определение тональности подразумевает классификацию по 3 классам: позитивная, негативная, нейтральная. Основной метрикой является точность — процент ответов, где ИИ правильно определил тональность.
Например, если из 100 ответов ИИ правильно определил тональность в 88 случаях, то точность = 88%.
Дополнительно мы отслеживали характер ошибок:
- Соседние ошибки — когда ИИ ошибся на один уровень (например, позитивную определил как нейтральную). Это менее критично.
- Противоположные ошибки — когда позитивный ответ определил как негативный или наоборот. Это серьёзная ошибка.
Категоризация: не только точность, но и полнота
Категоризация — более сложная задача: ИИ должен выбрать от 0 до 5 тегов из 58 возможных. Здесь недостаточно просто посчитать «правильно/неправильно». Нужны метрики, которые учитывают два типа ошибок:
1. Точность тегирования (Precision). Вычисляется по формуле:
Правильные теги ИИ / Все теги, которые поставил ИИ
Эта метрика показывает, насколько можно доверять тегам, которые ставит модель. Высокий показатель означает, что ИИ редко ставит лишние, неправильные теги. По сути, от точности тегирования зависит надежность классификации.
2. Полнота тегов (Recall). Показывает, сколько нужных тегов нашел ИИ по сравнению с теми, которые поставил эксперт. Показатель вычисляется по формуле:
Правильные теги ИИ / Все теги эксперта
Говоря простым языком, эта метрика измеряет способность модели правильно идентифицировать все релевантные ситуации. Высокий показатель означает, что ИИ редко пропускает важные теги.
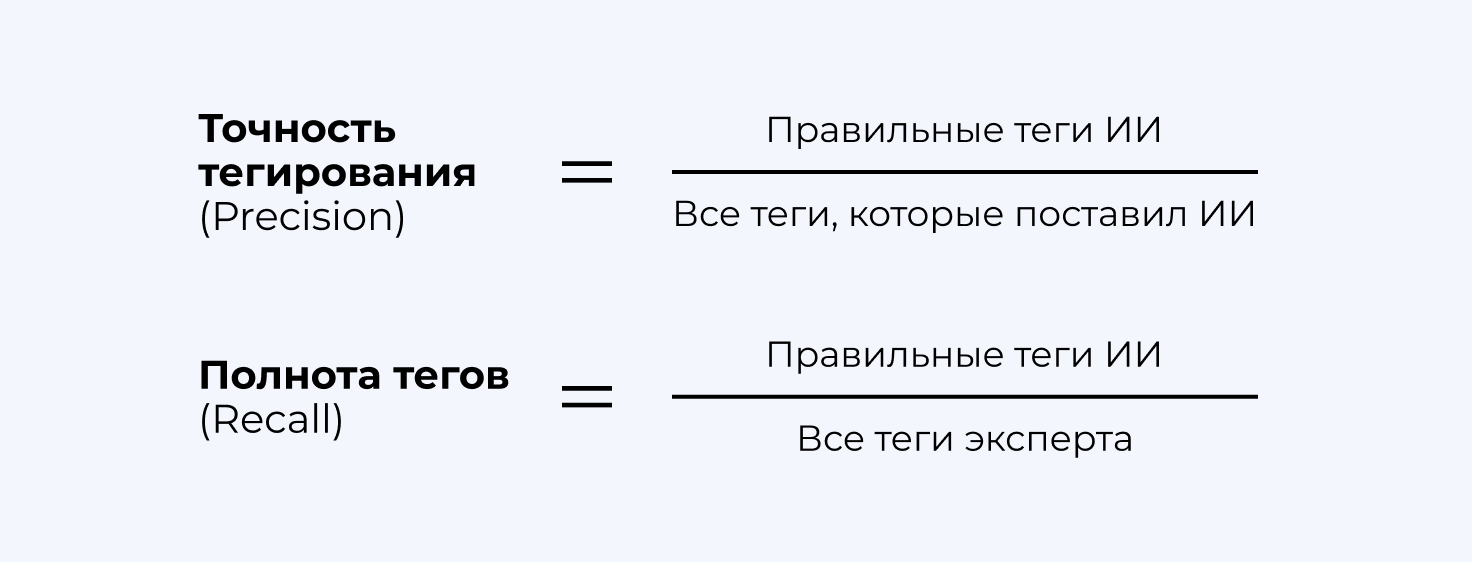
Формулы
Наглядный пример:
Ответ: «Яркое, красивое, летнее»
Эксперт поставил теги: Яркость/красочность, красиво, лето (3 тега)ИИ поставил теги: Яркость/красочность, красиво, солнечно, позитив (4 тега)
- Правильные теги ИИ: 2 (Яркость/красочность, красиво)
- Точность: 2 правильных / 4 поставленных = 50% (ИИ поставил 2 лишних тега)
- Полнота: 2 правильных / 3 нужных = 67% (ИИ пропустил 1 нужный тег «Лето»)

Тональность и категоризации в интерфейсе
Почему обе метрики важны:
- Высокая точность, низкая полнота → ИИ ставит мало тегов, но все они правильные
- Низкая точность, высокая полнота → ИИ ставит много тегов, включая лишние (много ложных результатов)
- Оба показателя высокие → оптимальный баланс: ИИ находит все нужные теги и не ставит лишние
Дообучение помогло улучшить одновременно обе метрики, а значит, модель стала проводить анализ и обработку данных и точнее, и полнее.
Результаты базовой модели
Определение тональности
Базовая модель YandexGPT Pro 5.1 показала следующие результаты при определении тональности:
- Полное совпадение с экспертом: 88,54%
- Соседние значения (ошибка на 1 уровень): 9,86%
- Противоположные значения: 1,60%
Результат 88,54% точности — это хороший показатель для базовой модели без дообучения на специфичных данных.
Категоризация (тегирование)
При категоризации текстов из 58 возможных тегов базовая модель показала:
- Полное совпадение: 50,54% Все теги совпали с тегами эксперта
- Точность: 78,90% Из поставленных ИИ тегов — правильных
- Полнота: 77,30% Из нужных тегов — поставил ИИ
Категоризация оказалась более сложной задачей: полное совпадение всех тегов достигнуто только в половине случаев. Это объясняется тем, что для тегирования используется большое количество категорий (58), что требует от модели более глубокого понимания контекста.
Результаты дообученной модели
Для дообучения мы использовали модель YandexGPT Lite 5 (меньшего размера, чем Pro). Модель обучалась на 60% данных, а тестировалась на оставшихся 40%.
Определение тональности
- Полное совпадение с экспертом: 92,28%
- Соседние значения (ошибка на 1 уровень): 6,58%
- Противоположные значения: 1,14%
Категоризация
- Полное совпадение: 69,99%
- Точность: 88,67%
- Полнота: 86,77%
Влияние дообучения
Дообучение модели привело к значительным улучшениям во всех метриках:
Тональность
Точность: +3,74 процентных пункта (+4,22%)
Базовая модель: 88,54%, дообученная: 92,28%
Ошибки (соседние): -33,27%
Базовая модель: 9,86%, дообученная: 6,58%
Ошибки (противоположные): -28,75%
Базовая модель: 1,60%, дообученная: 1,14%
Категоризация
Полное совпадение: +19,45 п.п. (+38,49%)
Базовая модель: 50,54%, дообученная: 69,99%
Точность: +9,77 п.п. (+12,38%)
Базовая модель: 78,90%, дообученная: 88,67%
Полнота: +9,47 п.п. (+12,25%)
Базовая модель: 77,30%, дообученная: 86,77%
Ключевые улучшения
- Прирост точности в определении тональности — 4,22% (с 88,54% до 92,28%).
- Улучшилось качество тегов — точность и полнота выросли примерно на 12%.
- В категоризации наблюдается прирост на 38,49% (с 50,54% до 69,99% полного совпадения).
Выводы и практическое применение
- Базовая модель показывает приемлемые результатыДаже без специального обучения YandexGPT Pro 5.1 достигла 88.54% точности в определении тональности и ≈78% точности и полноты в категоризации.
- Дообучение значительно улучшает эффективность обработкиПрирост точности составил 4% для тональности и 38% для категоризации. При этом дообученная модель меньшего размера (Lite) превзошла базовую модель большего размера (Pro).
- Наибольший эффект наблюдается на сложных задачахКатегоризация с 58 классами показала наибольший прирост от дообучения, что еще раз подтвердило гипотезу о его важности для специфичных задач с большим количеством категорий для классификации.
- 1600 примеров достаточно для дообученияДля получения значимого улучшения хватило ≈1600 размеченных текстов, т.е. дообучение можно проводить не только на больших проектах, но и на средних.

Изменения дообученной модели
Таким образом, даже базовый функционал ИИ анализа текстовых ответов в опросах работает достаточно хорошо. 88% точности в определении тональности позволяют получить общее представление об эмоциональной окраске ответов. Однако для более точного анализа целесообразно проводить дообучение модели, особенно если вы работаете со специфичной предметной областью или используете большое количество категорий.
Спасибо за внимание!
Команда ФОКУЗ.