

Заявка на звонок консультанта
Оставьте свои данные, мы свяжемся
с Вами в ближайшее время
с Вами в ближайшее время
Открытые ответы в исследованиях: методы обработки, категоризация, кластеризация и AI-подходы
9 минут
01.12.2025
- Никита ЛихановCustomer Research Manager в ФОКУЗРазвиваю направление исследований клиентского опыта и UX в ФОКУЗ. Специализируюсь на исследованиях клиентского опыта (CX), методиках опросов и анализе обратной связи.
Содержание
- Открытые текстовые ответы: то, что шкалы никогда не покажут
- Когда и зачем использовать открытые ответы
- Как правильно задавать открытые вопросы: рабочие правила
- Методы обработки открытых ответов
- Автоматические методы анализа: современный подход
- Как снижать шум и ошибки в текстовых данных (bias и мусорные ответы)
- Как соединять открытые ответы с количественными метриками
- Как ФОКУЗ помогает работать с открытыми ответами
- Ответы на частые вопросы
- Открытые текстовые ответы: то, что шкалы никогда не покажут
- Когда и зачем использовать открытые ответы
- Как правильно задавать открытые вопросы: рабочие правила
- Методы обработки открытых ответов
- Автоматические методы анализа: современный подход
- Как снижать шум и ошибки в текстовых данных (bias и мусорные ответы)
- Как соединять открытые ответы с количественными метриками
- Как ФОКУЗ помогает работать с открытыми ответами
- Ответы на частые вопросы
Открытые ответы давно стали стандартом в исследованиях: CX-команды, UX-исследователи и продакты внимательно читают комментарии, потому что именно там респонденты объясняют почему они поставили ту или иную оценку. Но по мере роста аудиторий и количества точек контакта комментариев становится слишком много — десятки, сотни, иногда тысячи строк текста.
Даже опытный аналитик тратит часы на ручное кодирование, а риски ошибок, субъективности и пропущенных смыслов только растут. Поэтому ключевой вызов сегодня — не «захотеть анализировать», а делать это быстро, масштабируемо и без потерь качества.
В этой статье разберём полный стек методов: от классического кодирования и категоризации до тематического моделирования, кластеризации и AI-анализаторов тональности — и покажем, как превратить хаотичный текст в точные и воспроизводимые инсайты.
Открытые текстовые ответы: то, что шкалы никогда не покажут
Открытые ответы — это неограниченные текстовые комментарии, где респонденты говорят своими словами, без шкал, шаблонов и подсказок. В отличие от количественных ответов, их нельзя «сложить» или посчитать среднее — они нелинейные, сырые и насыщенные контекстом.
В открытых ответах появляется всё, что не влезает в цифры: формулировки, эмоции, причины поведения, скрытые ожидания и мотивация. Именно здесь объясняется почему пользователи ставят низкий CSAT, уходят с шага онбординга или выбирают конкурентный продукт.
Такие данные используют на discovery-этапах, для генерации гипотез, проверки UX-сценариев, поиска барьеров в интерфейсе и анализа эмоционального восприятия. Это ценнейший пласт качественной информации — но работать с ним сложно вручную: много текста, высокая вариативность, ошибки аналитика и огромное время обработки.
Когда и зачем использовать открытые ответы
Открытые ответы — это лучший способ понять, почему люди делают то, что делают. Там, где шкалы показывают сухие цифры, текст даёт мотивацию, контекст и эмоции. Поэтому их стоит использовать в моментах, когда нужно «заглянуть под капот» поведения.
После ключевых метрик (NPS/CSAT/CES)
Оценка сама по себе ничего не объясняет. «8» может значить всё что угодно. Именно текст рассказывает, что клиенту понравилось, что раздражает и что нужно поправить. Часто пару сотен ответов дают куда больше инсайтов, чем любые графики.
- Никита ЛихановCustomer Research Manager в ФОКУЗВажно помнить, что даже сами шкалы подвержены разным искажениям (bias). Разные респонденты по-разному интерпретируют одинаковые значения (условно «семёрка» у минималистов = «девятка» у оптимистов). Открытые ответы помогают «поймать» смысл за оценкой и снизить риск неправильных выводов.
В UX/UI-тестах
Клики показывают путь, но не намерение. Открытые ответы помогают уловить барьеры («искал кнопку, но не понял иконку»), ожидания и логику действий. Для редизайна — бесценно.
В продуктовой разработке
Ранние пользователи оставляют комментарии, в которых часто больше инсайтов, чем в 20 закрытых вопросах. Они подсказывают, что добавить, что убрать, и какие сценарии вообще не работают.
В VoC-программах и EX-исследованиях
Голос клиента и голос сотрудника — это прежде всего слова. Тон, формулировки, повторяющиеся паттерны — всё это делает фидбэк куда глубже, чем цифры.
Для нахождения настоящих причин
Например, у вас NPS = 30. По цифрам — «ну, средне». Но только после кластеризации открытых ответов становится видно, что клиентов держат четыре боли: сроки, поддержка, неудобная навигация и путаница в тарифах. Без текстов вы этого не узнаете.
Как правильно задавать открытые вопросы: рабочие правила
Открытый вопрос сам по себе не гарантирует хорошего ответа. Если формулировка размытая или перегруженная, респонденты либо напишут одно слово, либо вообще пропустят поле. Поэтому к тексту таких вопросов нужно относиться почти как к UX-копирайтингу.
Подстраивайте язык под аудиторию. И в UX-интервью, и в онлайн-опросах принцип один: говорить на языке респондента, а не внутренним жаргоном команды. Перед запуском полезно протестировать формулировку на коллегах, которые не погружены в продукт.
Пример
Вместо: «Как вы оцениваете эффективность функционала авторизации?» лучше: «С какими трудностями вы столкнулись при входе в аккаунт?»
Избегайте двойных и многосоставных вопросов. Два вопроса в одном всегда ухудшают качество данных: респондент отвечает либо на первую часть, либо даёт поверхностную усредненную реакцию.
Пример
Плохо: «Что вам понравилось и что не понравилось в доставке?»; хорошо: «Что вам понравилось в доставке?» + отдельный вопрос про сложности.
Не направляйте респондента, но создавайте фокус. Легкая подсказка помогает человеку вспомнить опыт, но нельзя «подкладывать» ожидаемый ответ. Вопрос должен быть открытым, но не расплывчатым.
Пример
Плохо: «Что вам было сложно найти в каталоге?» (наводка): хорошо: «Расскажите, как вы искали нужный товар»
Просите конкретику, а не абстракции. Мы часто встречаем такое, что склонны отвечать общими словами: «нормально», «удобно», «долго». Просьба описать шаги, эмоции или события добавляет фактов, которые можно анализировать.
Пример
Вместо: «Опишите ваш опыт оплаты» лучше: «На каком шаге оплаты у вас возникли вопросы или паузы?»
Избегайте пустых конструкций вроде «Напишите всё, что считаете нужным». Такие фразы ведут либо к тишине, либо к нерелевантным текстам. Лучше задать вопрос так, чтобы человек понимал рамку и цель.
Пример
Вместо: «Напишите всё, что хотите сказать» лучше: «Если бы вы могли улучшить один аспект нашего сервиса, что бы это было и почему?»
Помогайте человеку вспоминать реальные события. Открытые ответы ценны тем, что содержат «полевую» информацию: эмоции, мотивы, препятствия. Чтобы её получить, вопрос должен активировать память о конкретной ситуации, а не просить об абстракциях.
Пример
«Вспомните последний раз, когда приложение зависло или работало медленно. Что вы сделали в этот момент?»
- Никита ЛихановCustomer Research Manager в ФОКУЗСтатья больше про методы обработки. Рекомендую почитать пару небольших, но очень хороших гайдов по составлению вопросов. Вот тут первый, а тут второй.
Методы обработки открытых ответов
Работа с открытыми ответами может идти разными путями — от полностью ручного анализа до полуавтоматических и полностью автоматизированных подходов. Выбор метода зависит от целей исследования, объёма данных и зрелости вашей VoC- или UX-практики.
Классика жанра — ручное кодирование, дающее максимальный контроль над контекстом, но плохо масштабируемое. Более системные команды используют готовые категориальные модели, что ускоряет обработку, но рискует пропустить новые темы. А при discovery-исследованиях эффективнее всего работают индуктивные подходы: категории рождаются прямо из данных, отражая реальную структуру пользовательских смыслов.
В целом методы можно применять одновременно: что-то на части данных, что-то на всех. Ручное кодирование помогает глубоко разобраться в мотивах. Категориальное — быстро масштабировать процессы. Индуктивное — находить новые инсайты, которых вы не ожидали увидеть.
Автоматические методы анализа: современный подход
В отличие от классического кодирования, алгоритмы могут одновременно учитывать семантику, контекст, эмоции и структуру текста. Большие языковые модели (LLM), тематическое моделирование, кластеризация и классификация — это инструменты, которые дополняют друг друга. Многие компании используют гибридный подход: сначала автоматическая обработка, затем ручная проверка «краевых случаев».
Ниже — сравнительная таблица ключевых автоматизированных методов, используемых в CX/UX/VoC-аналитике.
Автоматический анализ открытых ответов позволяет в 5−20 раз ускорить обработку фидбэка и открывает возможность находить темы, которые невозможно вытащить вручную. Главное — правильно сочетать методы: классификацию для стабильных сценариев, кластеризацию и топики для поиска инсайтов, и LLM — для интерпретации и проверки.
Как снижать шум и ошибки в текстовых данных (bias и мусорные ответы)
Текстовые ответы дают глубину, но одновременно несут высокий уровень шума: короткие реплики без смысла, эмоциональные всплески, дубликаты и спам искажают выводы. Чтобы сохранить качество данных, в VoC-программах и UX-исследованиях применяют комбинацию фильтров: автоматических (правила, ML) и ручных (верификация аналитиком).
Особенно важно чистить данные перед категоризацией и определению тональности: некачественные ответы формируют ложные «темы» и смещают полярность. Большинство проблем сводится к двум вопросам: как распознать неинформативные ответы и как отделить «сильный» негатив от просто эмоционального шума. Ниже рассказали об основных типах шума:
-
 Пустые и малосодержательные ответы. «Ок», «норм», «не знаю», «хз», один смайлик, случайные символы — удаляются автоматически. Это ответы без сигнала: они не добавляют инсайтов.
Пустые и малосодержательные ответы. «Ок», «норм», «не знаю», «хз», один смайлик, случайные символы — удаляются автоматически. Это ответы без сигнала: они не добавляют инсайтов. - Штампы и шаблонные фразы. «Всё хорошо», «всё понравилось», «ничего особенного». Такие ответы оставляют только в связке с количественной оценкой (например, CSAT), но исключают из тематического анализа и кластеризации.
- Дубликаты и массовый спам. Объединяются по одинаковому тексту или высокой текстовой схожести (cosine similarity). Если источник — бот или пользователь, копирующий один и тот же текст, ответы удаляются.
- Шум из-за обязательности поля. Если поле для текста сделали обязательным, пользователи часто пишут рандом («—», «нет», «/»). Неплохое решение — делать текстовый вопрос опциональным, но задавать направляющую формулировку («Расскажите, что именно можно улучшить…»).
- Никита ЛихановCustomer Research Manager в ФОКУЗНе весь негатив одинаково полезен. В текстах важно отличать эмоцию от факта. Если человек пишет конкретику — «оплата зависла», «курьер перепутал адрес» — это сигнал для анализа. Если же комментарий состоит только из общей эмоциональной реакции — «ужасно!», «ненавижу ваш сервис» — такое лучше относить в общий «фон недовольства», но не включать в узкие проблемные кластеры. Так модели остаются чище, а выводы — точнее.
Как соединять открытые ответы с количественными метриками
Открытые ответы раскрывают что стоит за цифрами NPS, CSAT или CES, поэтому их всегда полезно интерпретировать вместе. Например, при анализе NPS текстовые комментарии позволяют быстро выявить ключевые причины промоутерства и детракторства — от качества сервиса до UX-проблем. Это помогает не просто фиксировать оценку, а понимать, какие механики реально формируют лояльность.
В CSAT-трекинге текст часто указывает на корневые причины падений: долгие ответы поддержки, ошибки интерфейса, неудобная оплата. Анализ по сегментам (мобайл/десктоп, новый/опытный пользователь) помогает увидеть, где именно зарыт сбой в клиентском пути.

В CES открытые комментарии показывают барьеры: непонятные формулировки, скрытые кнопки, труднонаходимые разделы. Это особенно ценно в продуктовой разработке, где важно выявлять точки трения еще до релиза.
Для VoC-программ открытые ответы дают возможность отслеживать динамику тем по кварталам: какие жалобы участились, какие ушли, какие ожидания появились заново. Это превращает голос клиента из набора фраз в системную карту проблем и возможностей для роста.
Как ФОКУЗ помогает работать с открытыми ответами
ФОКУЗ автоматизирует самую тяжелую часть работы с текстовыми данными: сервис автоматически определяет тональность ответов, выделяет ключевые темы и предлагает готовые кластеры. Это позволяет быстрее увидеть реальные причины оценок, даже когда открытых комментариев — тысячи.
Кроме стандартных моделей, в ФОКУЗ можно настраивать собственные правила анализа: обучать категории под вашу специфику, добавлять индивидуальные теги, учитывать уникальную терминологию компании. Это помогает адаптировать аналитику под конкретный бизнес-процесс, а не под усредненные модели.
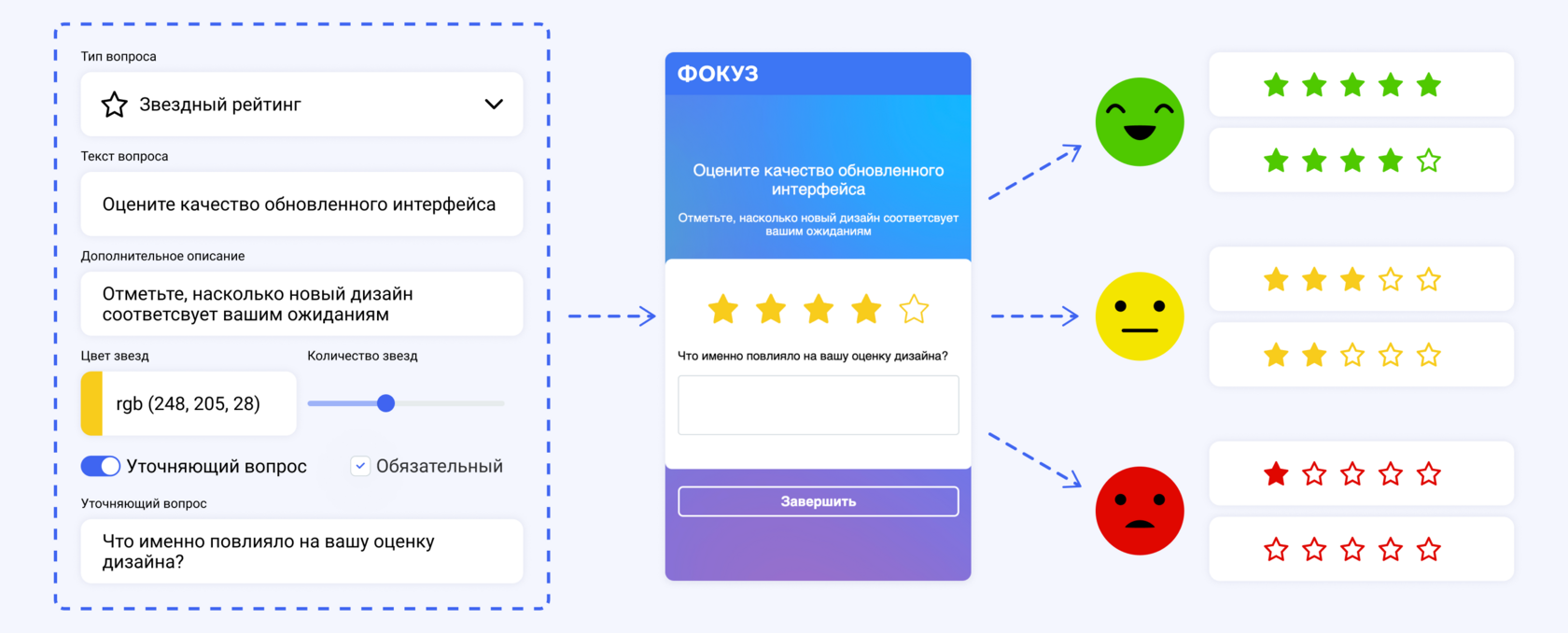
Все результаты можно автоматически отправлять в CRM, BI или сервисы для внутренней обработки. Благодаря этому открытые ответы перестают быть чем-то «вне контуров продукта» — они становятся частью вашей операционной системы принятия решений.
Ответы на частые вопросы
Нет. Открытые ответы работают лучше всего там, где важен контекст и эмоции: после NPS/CSAT, в UX-тестировании, при изучении причин поведения. Но в быстрых опросах или для мониторинга динамики достаточно закрытых шкал.
Обычно 1−2. Больше — резко снижает качество ответов и увеличивает количество пустых или формальных комментариев. Исключение — глубинные UX-исследования.
Да. Такие ответы не дают смысла, но влияют на алгоритмы, ухудшают кластеры и тональность. Их стоит автоматически фильтровать или выносить в отдельную категорию «неконструктивные».
AI быстрее (в десятки раз) и стабилен на больших объемах. Ручной анализ даёт более тонкий контекст, но хуже масштабируется и выше вариативность. На практике оптимально: AI как первичная разметка + выборочная ручная проверка. После обучения мы ожидаем минимум 80−90% точность.
По нашим исследованиям использование автоматической обработки позволят ускорить анализ во много раз. Есть кейсы, когда ускорение превышает 40 раз. Чем больше текстовых ответов, тем больше ускорение.